计算机学习数据中隐藏的规律的方法,是通过最小化预测值与实际值之间的误差来实现的。
除了通过前文讲述的最小二乘法,还可以通过梯度下降(Gradient Descent)实现,即通过多轮运算不断更新模型参数 $\boldsymbol{\theta}$ 的值,使得误差逐渐变小,直至达到一个较小的阈值。
什么是梯度下降#
当你站在高山的顶部,想以最快的速度下山,那么最快的方式是朝着最陡的方向行进
预测值与实际值之间的误差就是一座名为“误差”的高山,误差越大,山越高。
使用不同的模型参数,会得到不同的误差,相当于位于高山的不同位置。
你想通过改变模型参数,以最快的速度下山。
梯度下降,就是朝着令误差函数减小最快的方向更新参数,沿着最陡峭的方向下山。
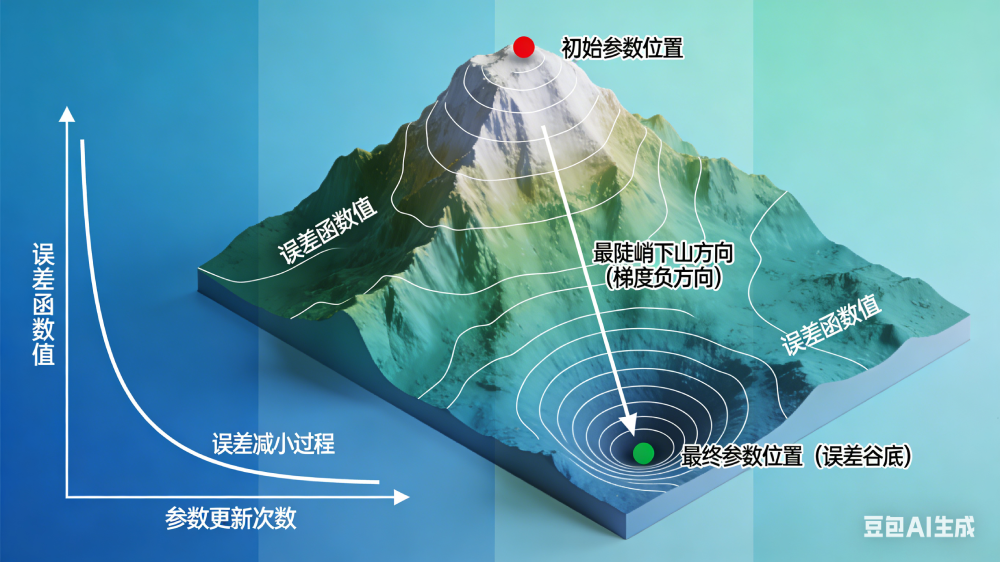
梯度下降算法#
梯度下降算法的核心思想是沿着损失函数梯度的负方向迭代更新参数,以达到损失函数的最小值。具体步骤如下:
设 $\epsilon_k > 0$ 为学习率(决定每次更新的步长),$k$ 为迭代计数器,$k = 1,2,\dots$
- 初始化:随机初始化参数 $\boldsymbol{\theta}$
- 迭代更新:当未收敛时:
- 从训练集中选取 $m$ 个样本 $\left \{ \boldsymbol{x} _1, \cdots , \boldsymbol{x} _m \right \}$ 及对应的标签 $\left \{ y_1, \cdots , y_m \right \}$
- 计算梯度 $\boldsymbol{g} \leftarrow \nabla_{\boldsymbol{\theta}} \frac{1}{m} \sum_{i=1}^m L(f(\boldsymbol{x} _{i},\boldsymbol{\theta}), y _{i})$,其中 $L$ 为损失函数,用于衡量单个样本的预测值 $f(\boldsymbol{x} _{i},\boldsymbol{\theta})$ 与真实标签 $y _{i}$ 之间的误差。在线性回归中,常用的损失函数是均方误差损失
- 计算更新 $\boldsymbol{\theta} \leftarrow \boldsymbol{\theta} - \epsilon_k \boldsymbol{g}$
计算梯度#
回到前面的例子,因为训练数据规模不大($N=1000$),我们把所有样本数据作为一个批次去训练。
均方误差损失函数为
\[ J(\boldsymbol{\theta}) := \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 = \frac{1}{N} \sum_{i=1}^{N} (y_i - \boldsymbol{x}_i \boldsymbol{\theta})^2 \]其中各个符号的定义请见上一篇文章
对各个参数取偏导数(Partial Derivative),便可以得到梯度$\boldsymbol{g}$
\[ \begin{aligned} \boldsymbol{g} := \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) \\ &= \nabla_{\boldsymbol{\theta}} \frac{1}{N} \sum_{i=1}^{N} (y_i - \boldsymbol{x}_i \boldsymbol{\theta})^2 \\ &= \frac{1}{N} \sum_{i=1}^{N} \nabla_{\boldsymbol{\theta}} (y_i - \boldsymbol{x}_i \boldsymbol{\theta})^2 \\ &= \frac{1}{N} \sum_{i=1}^{N} -2(y_i - \boldsymbol{x}_i \boldsymbol{\theta}) \boldsymbol{x}_i \\ &= \frac{2}{N} \sum_{i=1}^{N} (\boldsymbol{x}_i \boldsymbol{\theta} - y_i) \boldsymbol{x}_i \\ \end{aligned} \]得到的梯度$\boldsymbol{g}$是一个向量(shape $d \times 1$),其中的每一个值都分别代表$w_1$ ~ $w_d$的梯度。
代码实现#
在问题与建模一篇中,我们提供了数据集,现在请把它下载到本地。
# Using Gradient Descent (GD) to Solve Linear Regression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Set random seed for reproducibility
np.random.seed(42)
# read the CSV file
df = pd.read_csv('lifespan_data_full.csv')
# show the first 5 rows of the dataframe
print(df.head())
# extract the features and target variable
X0 = df[['parent_lifespan', 'gender', 'exercise_hours', \
'smoking', 'diet_health', 'sleep_hours', 'stress_level']].values
y0 = df['actual_lifespan'].values
# use the first 900 samples for training (100 samples are left for model evaluation)
X = X0[0:900]
y = y0[0:900]
# 标准化特征值和目标值
X_mean = X.mean(axis=0)
X_std = X.std(axis=0)
X_normalized = (X - X_mean) / X_std
y_mean = y.mean()
y_std = y.std()
y_normalized = (y - y_mean) / y_std
# ===================== 第三步:梯度下降法求解权重 =====================
def gradient_descent(X, y, learning_rate=0.01, epochs=300000, tol=1e-7):
"""
梯度下降法求解线性回归参数
参数:
X:未添加截距项的特征矩阵
y:因变量
learning_rate:学习率
epochs:最大迭代次数
tol:收敛阈值
返回:截距b,权重w,损失历史
"""
n_samples, n_features = X.shape
# 初始化权重(随机正态分布)
w = np.random.randn(n_features)
b = np.random.randn()
loss_history = [] # 记录损失变化
for epoch in range(epochs):
# 前向预测:y_pred = X·w + b
y_pred = np.dot(X, w) + b
# 计算均方误差损失
loss = np.mean((y_pred - y) ** 2)
loss_history.append(loss)
# 计算梯度
dw = (2 / n_samples) * np.dot(X.T, (y_pred - y)) # 权重梯度
db = (2 / n_samples) * np.sum(y_pred - y) # 截距梯度
# 更新参数
w -= learning_rate * dw
b -= learning_rate * db
# 收敛判断
if epoch > 0 and abs(loss_history[-1] - loss_history[-2]) < tol:
print(f"\n梯度下降在第{epoch}轮收敛!")
break
return b, w, loss_history
# 求解梯度下降解
b_norm, w_norm, loss_history = gradient_descent(X_normalized, y_normalized, learning_rate=0.01, epochs=150000)
# 将标准化空间的权重转换回原始空间以方便与标准答案做对比
w = w_norm * y_std / X_std
b = y_mean - np.dot(w_norm * y_std / X_std, X_mean) + b_norm * y_std
print("\n===== Linear Regression Solution =====")
print(f"Intercept (bias): {b:.4f}")
print(f"Weights: {np.round(w, 4)}")
# 绘制梯度下降损失曲线
plt.figure(figsize=(10, 4))
plt.plot(loss_history, color='blue', linewidth=1)
plt.title('Gradient Descent Loss Curve (MSE)', fontsize=12)
plt.xlabel('Iterations', fontsize=10)
plt.ylabel('Loss (MSE)', fontsize=10)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig('gradient-descent.png', dpi=150, bbox_inches='tight')
plt.show()
print("Image was saved as 'gradient-descent.png'")关键代码解释如下:
值标准化#
因为输入的字段(特征值和目标值)之间数值范围差异很大,而机器需要综合考虑它们的效果,所以需要先标准化(Normalized)特征值和目标值才能进行计算,避免个别大值字段影响独大。
# 计算梯度
# 标准化特征值和目标值
X_mean = X.mean(axis=0)
X_std = X.std(axis=0)
X_normalized = (X - X_mean) / X_std
y_mean = y.mean()
y_std = y.std()
y_normalized = (y - y_mean) / y_std推理时有两种方式:
- 保持标准化:对新输入 X 也做相同标准化,直接用 w_norm, b_norm 预测
- 转换回原始空间:用 w_orig, b_orig 直接对原始 X 预测
两种方式数学上等价。
梯度计算#
计算梯度的代码
# 计算梯度
dw = (2 / n_samples) * np.dot(X.T, (y_pred - y)) # 权重梯度
db = (2 / n_samples) * np.sum(y_pred - y) # 截距梯度与上面的梯度计算公式
\[ \boldsymbol{g} = \frac{2}{N} \sum_{i=1}^{N} (\boldsymbol{x}_i \boldsymbol{\theta} - y_i) \boldsymbol{x}_i \\ \]是一致的,都是每一个数据样本的特征值 $\times$(预测值与真实值的差)再求和。
权重转换回原始空间#
# 将标准化空间的权重转换回原始空间以方便与标准答案做对比
w = w_norm * y_std / X_std
b = y_mean - np.dot(w_norm * y_std / X_std, X_mean) + b_norm * y_std权重转换回原始空间的公式推导过程如下:
标准化变换为:
- X_norm = (X - X_mean) / X_std
- y_norm = (y - y_mean) / y_std
在标准化空间中学到的关系是:
y_norm = X_norm · w_norm + b_norm
将标准化公式代入:
(y - y_mean) / y_std = ((X - X_mean) / X_std) · w_norm + b_norm
两边乘以 y_std 并展开:
y - y_mean = X · (w_norm / X_std) · y_std - X_mean · (w_norm / X_std) · y_std + b_norm · y_std
整理成 y = X · w_orig + b_orig 的形式便得到:
- w_orig = w_norm * (y_std / X_std)
- b_orig = y_mean - (X_mean · w_norm) * (y_std / X_std) + b_norm * y_std
程序输出#
梯度下降在第410轮收敛!
===== Linear Regression Solution =====
Intercept (bias): 9.9104
Weights: [ 0.4009 5.9924 0.8038 -14.9764 8.9833 1.2996 7.0084]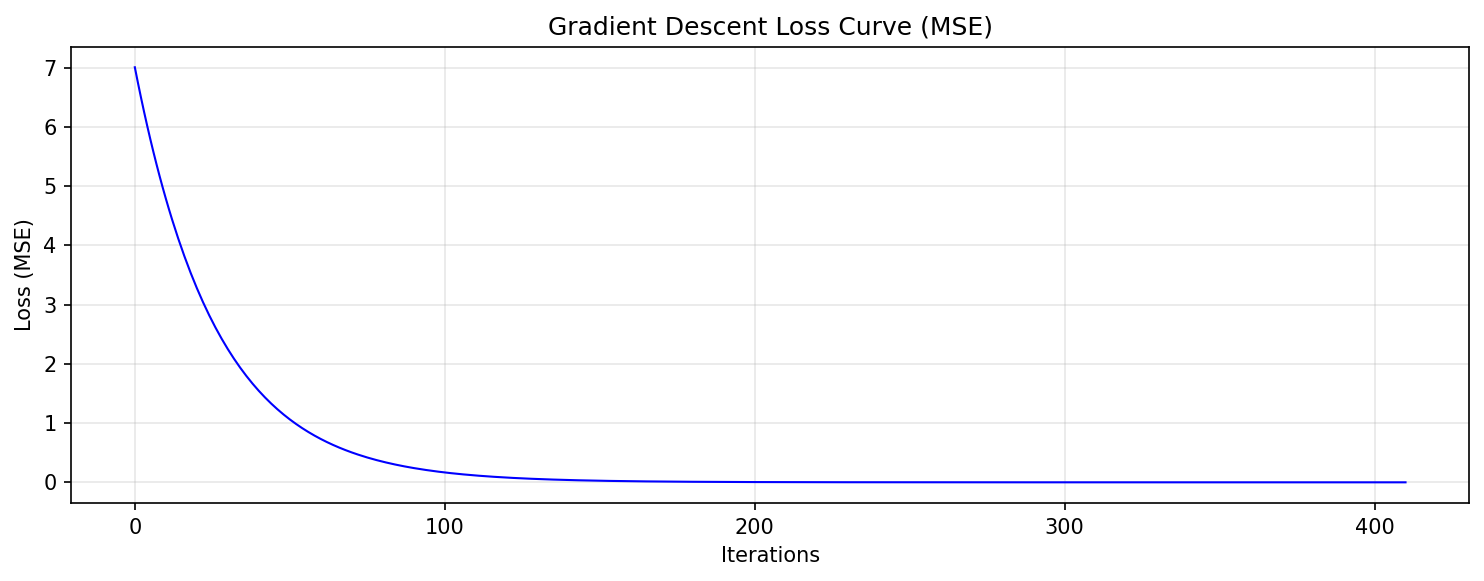
可以看到与标准答案非常接近。
与前的最小二乘法相比,梯度下降法的优势在于它可以处理大规模数据集,特别地当数据集包含噪声或异常值时,梯度下降法更稳定,但梯度下降过程中可能会落入局部最优解(山腰上的某个坑洼区域)而止步不前,此时可以调整参数$\boldsymbol{\theta}$的初始值(空降到不同的位置重新开始下破),或调大学习率$\epsilon_k$(调大迈步幅度)多次尝试。