要好用 AI Agent,我们需要先理解其核心:大语言模型(Large Language Model)
本文介绍应用 LLM,我们需要知道的知识。
人工智能#
人工智能经过几十年的发展,已经形成庞大的一系列分支
graph LR
AI[🤖 人工智能<br>Artificial Intelligence]
%% 技术分支
AI --> ML[📊 机器学习<br>Machine Learning]
AI --> DL[🧠 深度学习<br>Deep Learning]
ML --> Supervised[✅ 监督学习<br>Supervised Learning]
ML --> Unsupervised[🔎 无监督学习<br>Unsupervised Learning]
ML --> RL[🎮 强化学习<br>Reinforcement Learning]
Supervised --> ClassReg[🏷️ 分类 & 回归<br>Classification & Regression]
Unsupervised --> ClusterDim[📍 聚类 & 降维<br>Clustering & Dim. Reduction]
DL --> CNN[🖼️ CNN<br>卷积神经网络]
DL --> RNN[🔁 RNN / LSTM<br>循环神经网络]
DL --> Trans[🔄 Transformer]
DL --> GAN[🎨 GAN<br>生成对抗网络]
DL --> Diffusion[✨ 扩散模型<br>Diffusion Model]
DL --> GNN[🕸️ GNN<br>图神经网络]
Trans --> NLP[💬 NLP<br>自然语言处理]
Trans --> LLM[📚 大语言模型<br>Large Language Model]
Trans --> Multimodal[🎭 多模态模型<br>Multimodal Model]
%% 前沿方向
AI --> Emerging[🔮 前沿<br>Emerging AI]
Emerging --> Embodied[🤖 具身智能<br>Embodied Intelligence]
Emerging --> NeuroSymbolic[🧩 神经符号 AI<br>Neuro-symbolic AI]
Emerging --> EdgeAI[📱 边缘 AI<br>Edge AI]
%% 样式
style Trans fill:#FFD700,stroke:#DAA520,stroke-width:3px,color:#000
style NLP fill:#FFF8DC,stroke:#DAA520,stroke-width:2px
style LLM fill:#FFF8DC,stroke:#DAA520,stroke-width:2px
style Multimodal fill:#FFF8DC,stroke:#DAA520,stroke-width:2px当前大放异彩的 LLM 就是属于 Tranformer 这一支
深度学习#
深度学习是通过深度神经网络实现的,它模拟了人类的大脑神经网络结构。
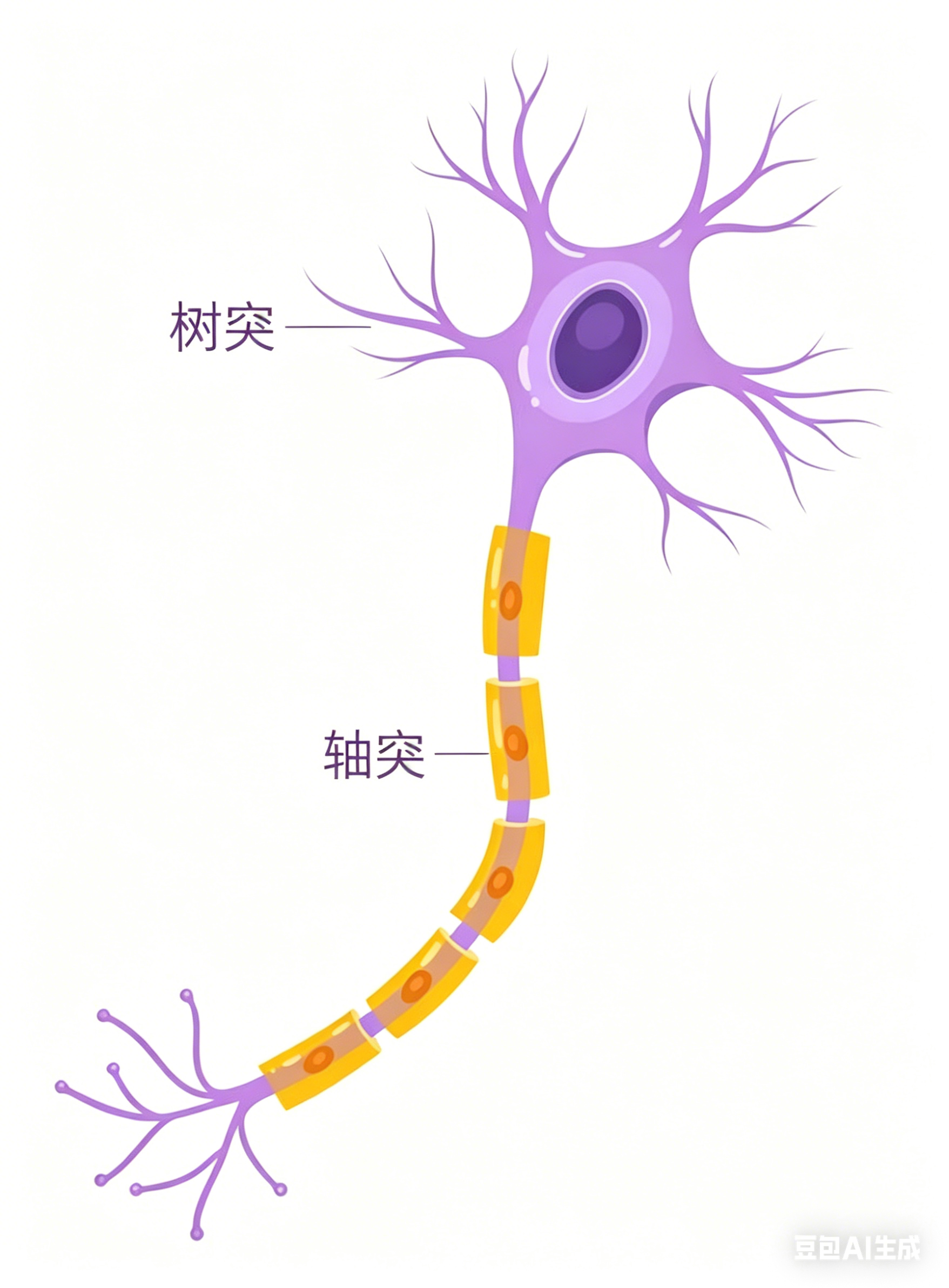

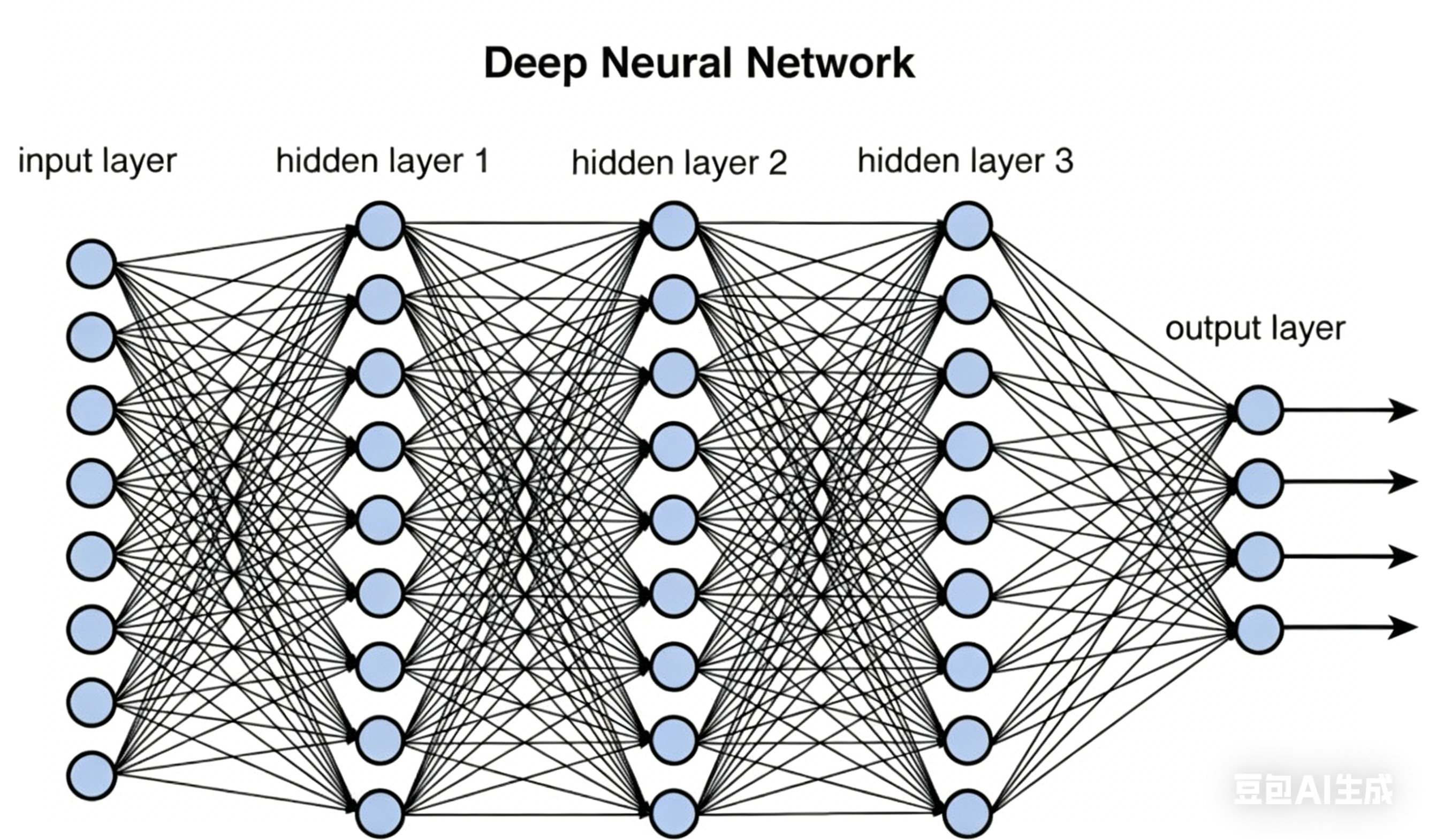
深度神经网络由大量神经元组成,每层神经元接收前一层输出的加权和,经过激活函数实现非线性变换后传递给下一层,最终到达输出层。输出层根据任务类型给出相应形式的输出:
- 多分类任务:经过 softmax 函数归一化为各类别的概率分布,常选择概率最高的作为预测结果
- 二分类任务:经 sigmoid 函数输出 0 到 1 之间的标量值,可视为正类概率
- 回归任务:无激活函数,直接输出线性结果
推理过程的数学表达式
加权求和激活#
\[ \boldsymbol{a}_{next} = \sigma(\boldsymbol{a}^T \boldsymbol{W} + \boldsymbol{b}) \]设按上一层 m 个神经元与当前层 n 个神经元全连接,其中
- $\boldsymbol{a}$ 为上一层的输出,shape 为 (m,1)
- $\boldsymbol{W}$ 为当前层的权重,shape 为 (m,n)
- $\boldsymbol{b}$ 为当前层的偏置,shape 为 (n,1)
- $\sigma$ 为激活函数,常见为:
- $relu(x) = max(0, x)$,输出 $\ge 0$, 主流
- $sigmoid(x) = \frac{1}{(1+e^{-x})}$,输出 0~1
- $tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}}$,输出 -1~1
Softmax#
\[ \text{softmax}(\boldsymbol{x}) = \begin{bmatrix} \text{softmax}(\boldsymbol{x})_1 \\ \text{softmax}(\boldsymbol{x})_2 \\ \cdots \\ \text{softmax}(\boldsymbol{x})_n \end{bmatrix} \]其中 $\boldsymbol{x}$ 为向量
\[ \text{softmax}(\boldsymbol{x})_i = \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}} \]一般的过程是通过训练得到权重 $\boldsymbol{W}$,封装成模型,再投放到应用场景中做推理。
不同的模型,会设计不同的神经网络架构,有不同的权重参数量。
深度学习是建立在概率论之上的一门技术,对它来说,没有 100% 的必然 —— 每次输出只是当前条件下概率较高的输出,而非逻辑运算后的确定结果
LLM 通常使用
temperature或top_p参数来控制输出采样策略
大语言模型#
大语言模型(LLM)是智能体的核心引擎和智力源泉。
现代的 LLM 基本是 Transformer 架构 或其变体,始于 Google Brain 团队于 2017 年发表的一篇论文《Attention Is All You Need》。
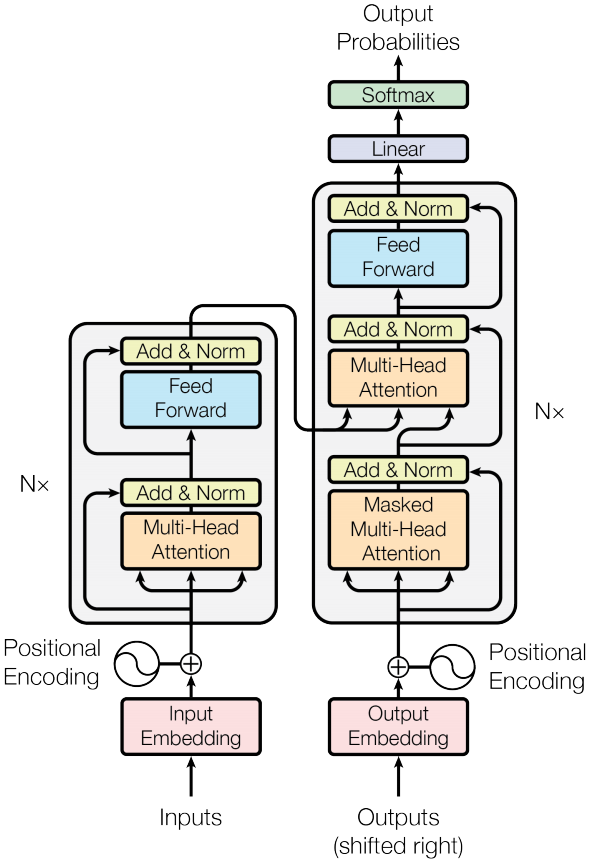
像 GPT 这一类生成大模型,只有右边的架构(Decoder-only),输出是一个字一个字往外蹦
像 BERT 这一类理解模型,只有左边的架构(Encoder-only),直接吐出整个语句的结果,用于分类、embedding 或意图理解
Transformer 是一种基于自注意力机制的深度神经网络架构,核心模块是多头自注意力结构。
通过投喂海量的通用知识,让其习得了其中的规律,并保存为模型的权重参数,这个过程称为预训练(Pre-training)。
之后需要经过价值对齐、监督微调等的后训练(Post-training)过程才能上线使用。
flowchart LR
A["🧠 <b>预训练</b><br/>海量知识里提取规律"]
B["🎯 <b>后训练</b><br/>价值对齐、监督微调"]
C["🚀 <b>推理</b><br/>部署使用"]
A --> B
B --> C
style A fill:#f0f8ff,stroke:#1890ff,stroke-width:2px,rx:12
style B fill:#fff0f6,stroke:#eb2f96,stroke-width:2px,rx:12
style C fill:#f6ffed,stroke:#52c41a,stroke-width:2px,rx:12
linkStyle 0 stroke:#ccc,stroke-width:2px
linkStyle 1 stroke:#ccc,stroke-width:2px模型以人类自然语言为基础习得,且权重参数量巨大,故名大语言模型
推理过程#
使用过程中,让 LLM 生成内容的过程成为推理(inference),大语言模型推理过程是这样的:
flowchart LR
A["🔤 <b>输入文本</b><br/>切分为 Token"]
B["📊 <b>Token 映射</b><br/>生成 Embedding 向量"]
C["🧠 <b>向量输入 LLM</b><br/>模型内部推理计算"]
D["📝 <b>解码生成</b><br/>自回归逐个输出 Token"]
A --> B
B --> C
C --> D
style A fill:#e6f7ff,stroke:#1890ff,rounded:true
style B fill:#f0f8fb,stroke:#00b96b,rounded:true
style C fill:#fff7e6,stroke:#faad14,rounded:true
style D fill:#fef0f0,stroke:#f5222d,rounded:true
例如 “我喜欢大自然” 会被拆分成 「我」、「喜欢」、「大」、「自然」 这四个 token。
人类自然语言里所有 token(词元)会组成一个词库。
词库里的每一个 token 都可以通过 embedding model(嵌入模型)生成对应的高维 embedding 向量。
embedding model ≠ LLM
生成的 embedding 向量不是随意的,而是对人类自然语言进行大量学习后摸索出规律,使得语义相关性高的 token 向量值也比较类似。
几个 embedding 例子:
- man ≈ 男人
- 美丽 ≈ 漂亮
- king - man + woman ≈ queen
不同的企业或开源社区,都可以训练出自己的 embedding model。
不同的 embedding model 的向量维度可以不一样。
例如
paraphrase-multilingual-MiniLM-L12-v2embedding model 的维度为 384。
想更深入了解 embedding 的知识,请看这篇:embedding
对 LLM 的调用,通过输入和输出的 token 计费。
LLM 以 token 为计量单位,token 是 AI 时代像“电”一样的存在,为能源消耗单位,消耗 token 得到推理结果
上下文长度#
LLM 是无状态的,只有权重与矩阵函数运算,所有的惊喜,都藏在输入里,输入称为提示词(prompt)。
有提示 LLM 产生期望输出之意
所以早期关于 LLM 的应用工程,叫提示词工程(Prompt Engineering)
stateDiagram-v2
human: 人类(用户)
LLM: 大语言模型(LLM)
human --> LLM: 请求
LLM --> human: 响应
style LLM fill:#ffdd57,stroke:#333,stroke-width:2px因为 LLM 无状态,所以每一次请求,都必须带上完整的上下文(context)信息,让 LLM 知道前面对话的内容
所以后来关于 LLM 的应用工程,也叫上下文工程(Context Engineering)
下面模拟一个含有多轮对会的过程,
由多轮对话组成的会话(session)
-
第一轮请求#
- 人类:你好,什么是白开水?
-
第一轮回复#
- 模型:白开水就是烧开之后冷却的饮用水,干净又健康。
-
第二轮请求#
- 人类:你好,什么是白开水?
- 模型:白开水就是烧开之后冷却的饮用水,干净又健康。
- 人类:那多喝白开水有什么好处?
-
第二轮回复#
- 模型:可以补充身体水分、促进代谢,缓解口干,帮助身体保持舒服的状态。
-
第三轮请求#
- 人类:你好,什么是白开水?
- 模型:白开水就是烧开之后冷却的饮用水,干净又健康。
- 人类:那多喝白开水有什么好处?
- 模型:可以补充身体水分、促进代谢,缓解口干,帮助身体保持舒服的状态。
- 人类:平时什么时候喝水最合适呢?
-
第三轮回复#
- 模型:早上起床后、运动结束后、口渴时、饭前半小时,都适合喝一点温水。
-
第四轮请求#
- 人类:你好,什么是白开水?
- 模型:白开水就是烧开之后冷却的饮用水,干净又健康。
- 人类:那多喝白开水有什么好处?
- 模型:可以补充身体水分、促进代谢,缓解口干,帮助身体保持舒服的状态。
- 人类:平时什么时候喝水最合适呢?
- 模型:早上起床后、运动结束后、口渴时、饭前半小时,都适合喝一点温水。
- 人类:能不能给我整理 3 条简单的喝水小建议?
-
第四轮回复#
- 模型:① 不要等到很渴才喝水;② 少量多次慢慢喝;③ 少喝饮料,多用白开水代替。
-
第五轮请求#
- 人类:你好,什么是白开水?
- 模型:白开水就是烧开之后冷却的饮用水,干净又健康。
- 人类:那多喝白开水有什么好处?
- 模型:可以补充身体水分、促进代谢,缓解口干,帮助身体保持舒服的状态。
- 人类:平时什么时候喝水最合适呢?
- 模型:早上起床后、运动结束后、口渴时、饭前半小时,都适合喝一点温水。
- 人类:能不能给我整理 3 条简单的喝水小建议?
- 模型:① 不要等到很渴才喝水;② 少量多次慢慢喝;③ 少喝饮料,多用白开水代替。
- 人类:好的,帮我简单总结一下这段内容。
-
第五轮回复#
- 模型:简单来说,白开水健康有益,日常要养成定时、少量多次喝水的好习惯,少喝含糖饮料。
你发现了吗?会话雪球越滚越大!
以上例子是按类似 OpenAI 的
/v1/chat/completionsChat Completions API 视觉展开的。如果采用较新的/v1/responsesResponses API,不用每次都把会话上下文传过去,只需要发送最新的问题即可,服务端会维护会话的上下文,接口会更简洁,减少了传输开销,但 token 消耗并不会因此而减少。
但在 LLM 里,对每一次请求,从 prompt 的第一个 token 开始到已经生成的 token,都会参与到自注意力运算才能输出下一个 token,
就好像一本几百页的小说,开篇的一句话,也会影响到结尾处的结局
所以每一个 LLM,都有一个叫上下文长度(context length)的硬指标,来限定 prompt token 加上能生成 token 数的上限(以 token 个数为计量单位)
例如,模型
DeepSeek-V3.2的上下文长度为 128K,MiniMax-M2.7200K,Qwen3.6-Plus为 1M
过长的上下文会让 KV 缓存爆炸、单 token 平均注意力降低,但更核心的问题是模型能否在海量 tokens 中准确定位关键信息
随着大模型的发展,context length 可能会越来越大,但限于算力和显存资源,是不可能无限增长的,所以上下文工程就是围绕这个问题而诞生的工程方法
我们在日常的 LLM 使用中,最关心的莫过于当前 context length 还剩下多少。
事实上,LLM 所在的服务一般是有缓存(KV Cache)的,因为通常一个 session 都会有多轮对话,每一次轮对话的输入 prompt 的前面部分都是一样的,而 prompt 里所有的 token 都是需要映射为 K(Key) 和 V(Value) 向量并参与到后面每个 token 的生成,所以 LLM 服务通常会缓存 token 的 KV,用于后续对话的计算
想更深入了解自注意力机制,请看这篇:自注意力机制
结构化输出#
像前面的例子,人类与 LLM 的对话,一般是输出一段自然语言文本,为了支持流程程序化,现在很多 LLM 都支持结构化输出(一般是 JSON 格式)。
stateDiagram-v2
direction LR
human: 人类(用户)
LLM: 大语言模型(LLM)
human --> LLM: 用户请求,要求 JSON 回复
LLM --> human: 回复 JSON 格式
style human fill:#a8e6cf,stroke:#333,stroke-width:2px
style LLM fill:#ffd93d,stroke:#333,stroke-width:2pxLLM 结构化输出的例子
# copied and modified from `https://api-docs.deepseek.com/zh-cn/guides/json_mode`
import json
from openai import OpenAI
client = OpenAI(
base_url="https://api.deepseek.com",
)
system_prompt = """
用户将提供一些考试文本。请从中解析出「问题」与「答案」,并以 JSON 格式输出。
示例输入:
世界上最高的山峰是什么?珠穆朗玛峰。
示例 JSON 输出:
{
"question": "世界上最高的山峰是什么?",
"answer": "珠穆朗玛峰"
}
"""
user_prompt = "世界上最长的河流是哪条?尼罗河。"
messages = [{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
response_format={
'type': 'json_object'
}
)
print(response.choices[0].message.content)输出结果
{
"question": "世界上最长的河流是哪条?",
"answer": "尼罗河"
}有了这个能力,我们可以把 LLM 的结构化输出交由下游的程序继续处理了,即可把 LLM 串联到程序的工作流中,实现智能自动化。
接下来看看结构化输出的升级版 —— LLM 工具调用。
工具调用#
这是作为一名程序员,大语言模型最让我惊喜的地方
所谓工具调用(tool calling,也叫 function calling),就是 LLM 跟据上下文判断用户意图,生成函数调用的结构化输出。
典型的流程是这样子的:
stateDiagram-v2
direction LR
human: 人类(用户)
agent: 智能体(AI Agent)
LLM: 大语言模型(LLM)
tool: 外部工具(Tool)
human --> agent: 1.用户请求
agent --> LLM: 2.提交推理请求
LLM --> agent: 3.输出工具调用意图
agent --> tool: 4.执行工具调用
tool --> agent: 5.返回原始结果
agent --> LLM: 6.回传工具结果
LLM --> agent: 7.生成整合回答
agent --> human: 8.回复用户
style human fill:#a8e6cf,stroke:#333,stroke-width:2px
style agent fill:#dcedc1,stroke:#333,stroke-width:2px
style LLM fill:#ffd93d,stroke:#333,stroke-width:2px
style tool fill:#ff8b94,stroke:#333,stroke-width:2px人类> 佛山的天气怎么样?
模型> 【调用工具】: get_weather, 【参数】: {"location": "佛山"}
工具> 多云,气温 24-30°C,湿度 69%,微风。
模型> 根据查询结果,佛山今天的天气情况如下:
- **天气状况**:多云
- **气温**:24-30°C
- **湿度**:69%
- **风力**:微风
今天佛山天气比较舒适,温度适中,多云天气,微风习习,适合外出活动。建议穿着轻薄衣物即可。LLM 工具调用的 Python 代码
# copied and modified from `https://api-docs.deepseek.com/zh-cn/guides/tool_calls`
import json
from openai import OpenAI
def get_weather(location: str) -> str:
"""Get weather of a location (demo with fixed data)."""
weather_data = {
"北京": "小雨,气温 15-22°C,湿度 80%。",
"上海": "晴,气温 22-28°C,湿度 50%。",
"广州": "多云,气温 25-30°C,湿度 70%。",
"佛山": "多云,气温 24-30°C,湿度 69%,微风。",
}
return weather_data.get(location, f"{location}天气:数据暂缺,请稍后再试。")
# 注册工具函数
TOOL_FUNCTIONS = {
"get_weather": get_weather,
}
def send_messages(messages):
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools
)
return response.choices[0].message
client = OpenAI(
base_url="https://api.deepseek.com",
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气,用户需要先提供具体位置。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如广州",
}
},
"required": ["location"]
},
}
},
]
messages = [{"role": "user", "content": "佛山的天气怎么样?"}]
print(f"人类>\t {messages[0]['content']}")
message = send_messages(messages)
messages.append(message)
tool = message.tool_calls[0] if message.tool_calls else None
if not tool:
# 无工具调用意图,正常回复用户
print(f"模型>\t {message.content}")
else:
print(f"模型>\t 【调用工具】: {tool.function.name}, 【参数】: {tool.function.arguments}")
# 检测到 LLM 的工具调用意图,发起工具调用
args = json.loads(tool.function.arguments)
func_name = tool.function.name
func = TOOL_FUNCTIONS.get(func_name)
tool_result = func(args["location"])
print(f"工具>\t {tool_result}")
# 向 LLM 返回工具调用原始结果
messages.append({"role": "tool", "tool_call_id": tool.id, "content": tool_result})
message = send_messages(messages)
print(f"模型>\t {message.content}")编程语言是目前为止最精确的意图表达方式,不是自然语言,不是图片,是代码。自然语言还需要一个翻译层,而代码可以直接转换成行动
LLM 的 tool calling 能力是 AI Agent 能够接管世界的开始,是这位“文科生”由文转理的起点。 它能读懂自然语言意图,然后生成代码,并交由 AI Agent 执行。 这意味着 AI 不再只是回答问题、给出建议的聊天助手,而是可以直接作用于物理世界的机器人
LLM 接口#
目前市面上的 LLM,大多兼容以下接口之一
OpenAI Chat Completions /v1/chat/completions(最主流)
from openai import OpenAI
client = OpenAI(
base_url="<MODEL_BASE_URL>",
api_key="<YOUR_API_KEY>",
)
# export OPENAI_BASE_URL=${MODEL_BASE_URL}
# export OPENAI_API_KEY=${YOUR_API_KEY}
response = client.chat.completions.create(
model="<MODEL_NAME>",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hi, how are you?"},
],
extra_body={"enable_thinking": True},
)OpenAI Responses /v1/responses(较新)
from openai import OpenAI
client = OpenAI(
base_url="<MODEL_BASE_URL>",
api_key="<YOUR_API_KEY>",
)
# export OPENAI_BASE_URL=${MODEL_BASE_URL}
# export OPENAI_API_KEY=${YOUR_API_KEY}
response = client.responses.create(
model="<MODEL_NAME>",
input="Hi, how are you?",
extra_body={"enable_thinking": True},
)Anthropic /v1/messages
import anthropic
# export ANTHROPIC_BASE_URL=${MODEL_BASE_URL}
# export ANTHROPIC_API_KEY=${YOUR_API_KEY}
client = anthropic.Anthropic()
message = client.messages.create(
model="<MODEL_NAME>",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)这就是为什么明明你调用的不是 OpenAI 或 Anthropic 的模型,却在使用他们的 SDK 的原因。 只要设置了正确的 URL 和 API Key,服务端会做接口兼容
此外有些模型厂家会有自己格式的接口,例如 Google Gemini 原生接口格式,阿里云百炼的 DashScope 接口格式。
也有像 OpenRouter 这样的 LLM Gateway,提供接口代理访问其它大模型(兼容 OpenAI Chat Completions 接口)
LLM 也可以本地部署,例如使用 Ollama,它提供了自己的接口格式